- Published on
BERT Paper
- Authors

- Name
- Brian
- @blackorangebros
BERT之前的预训练模型
- 模型结构
- 单向,仅从左到右或者从右到左(unidirectional)
- 即使是双向的,也是简单的left-to-right, right-to-left, 然后concat起来
- 下游task使用:feature-based and fine-tuning
BERT的主要改进
- 模型结构
- 双向,使用MLM(masked language model),即随机丢掉一些token,预测这些token。 有点像stable diffusion的思想,把画画的过程倒过来,涂抹掉一些,让AI尝试来还原
- 下游使用:仅需要在预训练模型的基础上,适配input,增加output layer
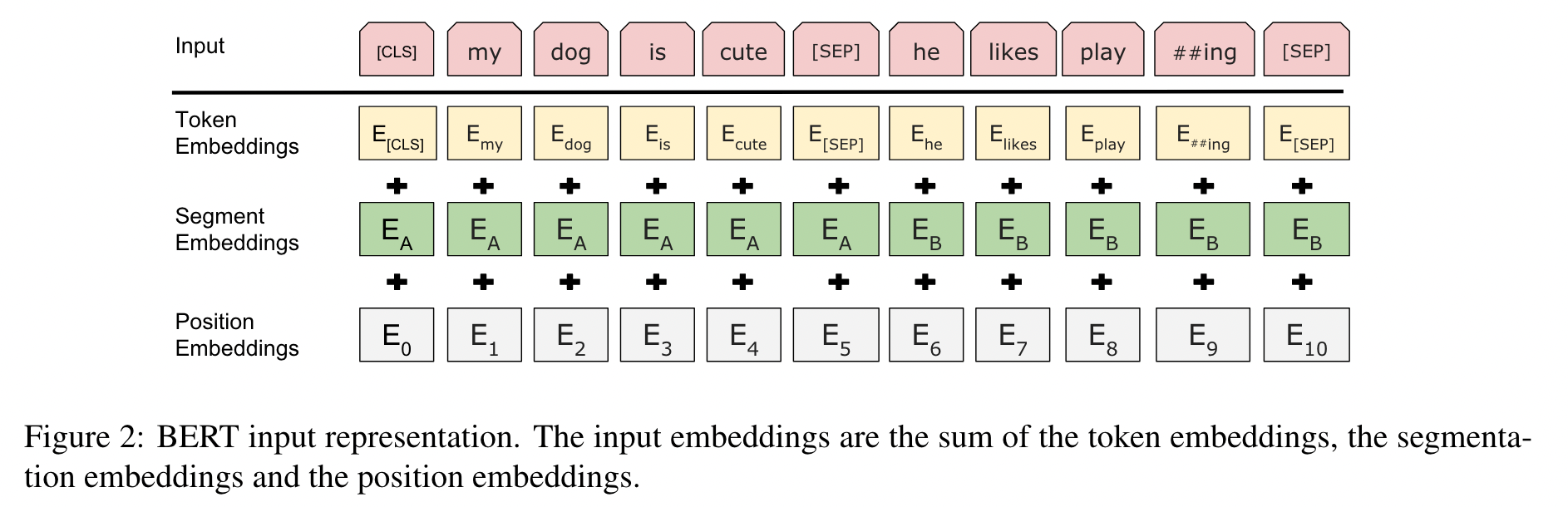
Embedding
- 为了预训练模型能兼容更多的下游任务,设计上尽可能灵活通用。 比如输入sentence,可以是任何连续的text,而不是语言学狭义上的sentence。 比如QA任务,将QA concat起来,用[SEP] 来分割
- 为了区别不同的sentence中的token,加入了一个learned embedding,叫作segment embedding,见Figure 2
预训练2个任务
- MLM(Masked LM) 随机mask 15%的WordPiece tokens。但是,如果将trainging data中的15% 同词token完全、[MASK], fine-tuning的时候就不会出现该token。 为了缓解这个问题,只在80%的情况下replace为[MASK], 10%的情况下替换为其他随机token,10%情况下不做替换
使用交叉熵预测mask token的原始word
- NSP(Next Sentence Prediction)
sentence pair选择:50% B(labeled as NotNext)在原始语料里是A的下一句话; 50%是corpus中的随机sentence
5.1节的实验证实,NSP在pre-train阶段,对QA和NLI两类任务有益
在之前类似NSP的任务中,只将sentence embedding层用于下游任务。 BERT是将所有parameters用于初始化下游任务的model
语料
- BooksCorpus (800M words) (Zhu et al., 2015)
- English Wikipedia (2,500M words),过滤了lists, tables, and headers等
document-level的语料,要好于shuffled sentence-level。因为有更长的上下文
Fine-tuning BERT
BERT将pair concat,然后整体双向self-attention
分类任务中,将[CLS]的vector作为聚合表征,输入output layer,映射到K个label上